
Build a Budget Deep Learning Box
Dr. George Jen
There is a myth that a good deep learning machine got to be expensive, it does not have to be that way. I just have done it on a shoe string, and I want to compare it with enterprise level real server.
Here is what I have done:
I. Build the machine:
I do my own HW design:
1. Mainstream Intel CPU motherboard, supporting up to 7th gen Intel core CPU (Kirby Lake), they are widely available and cheap. The motherboard I have chosen is
Gigabyte GA-Z170XP-SLI, which support Intel 7th gen CPU and up to 64GB memory, and up to 3 full length video cards. It has pretty good reviews on Amazon and I plan to buy this motherboard and an Intel i3 CPU.
Why not 7th gen i7? The answer is in machine learning, CPU is merely an initiator only, it is not an executor, it only does user request intake, prepare data and present final classification result. GPU is an executor. Since I set the budget, I bought one from eBay for $61 plus shipping.
Gigabyte GA-Z170XP-SLI Motherboard + Intel Celeron G3900 CPU Processor
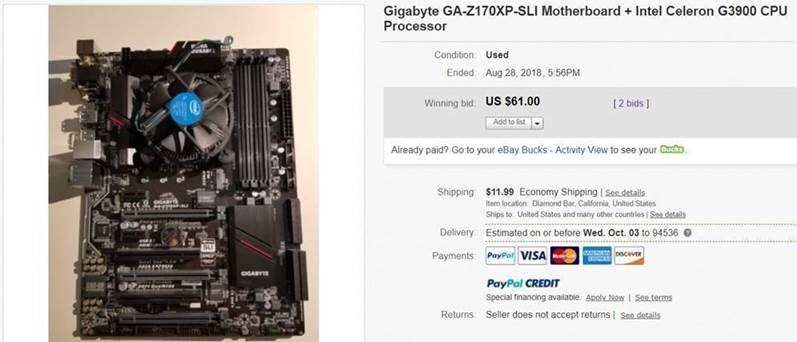
The guy threw in an Intel Celeron G3900 CPU Processor free, which is Intel 7th gen CPU, just the lowest end of its product family, with 2 cores. That would be allright, it will do its job well as initiator. That saves me time to buy and install a new Intel processor.
2. Then I bought a NVIDIA GeForce GTX 1070 Ti SC Black Edition on eBay too. Why GTX 1070 ti? Because it has best price/performance ratio. It has 8GB GDDR onboard memory and 2400+ cuda cores, but vastly discounted because NVidia is releasing new GTX 20XX series.
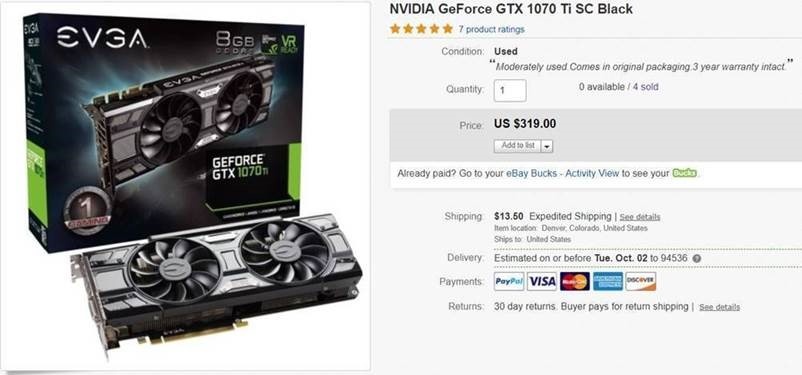
I got it on eBay for $320, a good deal.
3. Then I headed to local computer parts superstore, bought a mid tower case with 5 case fans ($60), I design my own air flow for proper cooling and 16GB memory ($150), and an M2 PCIe 256GB SSD ($70). I got a 600W power supply laying around, so just use it. I have a 1TB HD laying around, just use it as backup place.
4. Took a weekend to assemble, here is assembled deep learning box:

5. Install Ubuntu 18.04, easy, completed quickly. Then follow deep learning box setup instructions:
http://www.erpcomputing.com/deep-learning-using-keras
Software installation is done within 2 hours.
The machine is powerful for what the intended purpose:
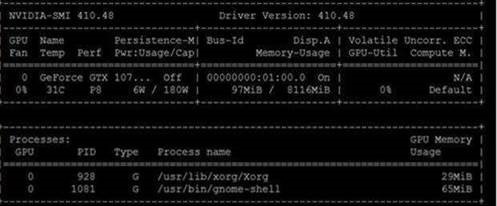
And it has 2400+ cores:

It can run up to 2048 concurrent threads. Someone may argue there can be thousands of threads in the OS queue, but they are NOT concurrent threads, the number of concurrent threads is limited to the number of available cores in the machine, meaning vast majority of the threads are in wait state.
Why large concurrent thread capacity is so important in deep learning? Because at the center of deep learning, it is matrix and vector computation, like matmul() (matrix multiplication):
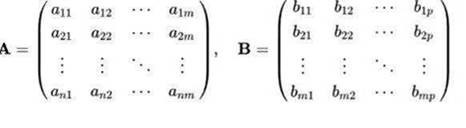

C=A*B
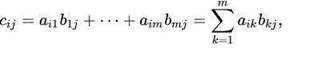
Each c(j,j) can be calculated in parallel at the same time if the machine can support large number of concurrent threads.
If you have to do it on a regular computer, you would have to do it with nested loop, on i and j. When you do nested loop, you are doing it in serial. So the difference in speed is obvious.
6. I built this machine in a shoe string,
Total cost:
Gigabyte GA-Z170XP-SLI Motherboard + Intel Celeron G3900 CPU Processor: $61+$12 (shipping) = $73
16GB memory: $150
256GB SSD: $70
NVIDIA GeForce GTX 1070 Ti SC Black Edition: $320
Mid Tower case: $60
Power supply (600W): $50
Total: $723, adding sales taxes, less than 850 bucks
II. Next step, I want to compare with this machine with a server with decent number of CPU cores and decent amount of memory and see how this budget built machine stacked up.
I ran a benchmark on image recognition on hand written digits, a popular classic starter on deep learning with neural network classification. Dataset is called MNIST (http://yann.lecun.com/exdb/mnist/), classification algorithm is RNN (recurrent neural network) that is having matrices and vectors computation.
I timed and ran the python code on a server with an enterprise Linux powered bare metal server with 2 Xeons (48 CPU) cores with 256GB RAM, without graphics card,
# grep "processor" /proc/cpuinfo | wc -l
48
# free
total used free shared buff/cache available
Mem: 263836644 8586980 28754508 1697668 226495156 252470536
Swap: 2097148 0 2097148
It took 27 minute 32 second elapse time, to train the machine to understand hand written with Testing Accuracy: 0.8984375
real 5m24.519s
user 27m32.158s
sys 6m12.759s
Then I ran the same Python code on my machine with 1 Celeron (2 core), 16GB RAM, a NVidia GTX 1070 ti with 8GB DDR5 and 2400+ cuda cores
It took 1 minute 21 second elapse time, to train the machine to understand hand written with Testing Accuracy: 0.8828125
Testing Accuracy: 0.8828125
real 1m22.601s
user 1m21.002s
sys 0m7.588s
My machine significantly outperforms the enterprise server by nearly 4X.
Following are the testing transcript:
1. On a server with 48 CPU cores/256GB RAM:
[
# time python recurrent_network.py
/root/anaconda3/lib/python3.6/site-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.
from ._conv import register_converters as _register_converters
WARNING:tensorflow:From recurrent_network.py:21: read_data_sets (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.
Instructions for updating:
Please use alternatives such as official/mnist/dataset.py from tensorflow/models.
WARNING:tensorflow:From /root/anaconda3/lib/python3.6/site-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:260: maybe_download (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version.
Instructions for updating:
Please write your own downloading logic.
WARNING:tensorflow:From /root/anaconda3/lib/python3.6/site-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:262: extract_images (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.
Instructions for updating:
Please use tf.data to implement this functionality.
Extracting /tmp/data/train-images-idx3-ubyte.gz
WARNING:tensorflow:From /root/anaconda3/lib/python3.6/site-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:267: extract_labels (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.
Instructions for updating:
Please use tf.data to implement this functionality.
Extracting /tmp/data/train-labels-idx1-ubyte.gz
WARNING:tensorflow:From /root/anaconda3/lib/python3.6/site-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:110: dense_to_one_hot (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.
Instructions for updating:
Please use tf.one_hot on tensors.
Extracting /tmp/data/t10k-images-idx3-ubyte.gz
Extracting /tmp/data/t10k-labels-idx1-ubyte.gz
WARNING:tensorflow:From /root/anaconda3/lib/python3.6/site-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:290: DataSet.__init__ (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.
Instructions for updating:
Please use alternatives such as official/mnist/dataset.py from tensorflow/models.
WARNING:tensorflow:From recurrent_network.py:77: softmax_cross_entropy_with_logits (from tensorflow.python.ops.nn_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Future major versions of TensorFlow will allow gradients to flow
into the labels input on backprop by default.
See @{tf.nn.softmax_cross_entropy_with_logits_v2}.
2018-09-27 12:43:54.968363: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
Step 1, Minibatch Loss= 2.9389, Training Accuracy= 0.141
Step 200, Minibatch Loss= 2.0791, Training Accuracy= 0.320
Step 400, Minibatch Loss= 1.9905, Training Accuracy= 0.328
Step 600, Minibatch Loss= 1.7382, Training Accuracy= 0.414
Step 800, Minibatch Loss= 1.6303, Training Accuracy= 0.484
Step 1000, Minibatch Loss= 1.6032, Training Accuracy= 0.469
Step 1200, Minibatch Loss= 1.5498, Training Accuracy= 0.523
Step 1400, Minibatch Loss= 1.3419, Training Accuracy= 0.578
Step 1600, Minibatch Loss= 1.4288, Training Accuracy= 0.539
Step 1800, Minibatch Loss= 1.2678, Training Accuracy= 0.609
Step 2000, Minibatch Loss= 1.2080, Training Accuracy= 0.617
Step 2200, Minibatch Loss= 1.2996, Training Accuracy= 0.641
Step 2400, Minibatch Loss= 1.1556, Training Accuracy= 0.656
Step 2600, Minibatch Loss= 1.2326, Training Accuracy= 0.617
Step 2800, Minibatch Loss= 1.0982, Training Accuracy= 0.656
Step 3000, Minibatch Loss= 1.1160, Training Accuracy= 0.680
Step 3200, Minibatch Loss= 0.9884, Training Accuracy= 0.680
Step 3400, Minibatch Loss= 1.1071, Training Accuracy= 0.641
Step 3600, Minibatch Loss= 1.0522, Training Accuracy= 0.688
Step 3800, Minibatch Loss= 0.8391, Training Accuracy= 0.750
Step 4000, Minibatch Loss= 1.1120, Training Accuracy= 0.609
Step 4200, Minibatch Loss= 0.8780, Training Accuracy= 0.727
Step 4400, Minibatch Loss= 0.8597, Training Accuracy= 0.727
Step 4600, Minibatch Loss= 0.8418, Training Accuracy= 0.734
Step 4800, Minibatch Loss= 0.7465, Training Accuracy= 0.750
Step 5000, Minibatch Loss= 0.8330, Training Accuracy= 0.742
Step 5200, Minibatch Loss= 0.6910, Training Accuracy= 0.781
Step 5400, Minibatch Loss= 0.8432, Training Accuracy= 0.742
Step 5600, Minibatch Loss= 0.6543, Training Accuracy= 0.781
Step 5800, Minibatch Loss= 0.8574, Training Accuracy= 0.750
Step 6000, Minibatch Loss= 0.7193, Training Accuracy= 0.781
Step 6200, Minibatch Loss= 0.7891, Training Accuracy= 0.781
Step 6400, Minibatch Loss= 0.7406, Training Accuracy= 0.828
Step 6600, Minibatch Loss= 0.6304, Training Accuracy= 0.797
Step 6800, Minibatch Loss= 0.5800, Training Accuracy= 0.844
Step 7000, Minibatch Loss= 0.6605, Training Accuracy= 0.734
Step 7200, Minibatch Loss= 0.7147, Training Accuracy= 0.734
Step 7400, Minibatch Loss= 0.5023, Training Accuracy= 0.836
Step 7600, Minibatch Loss= 0.5748, Training Accuracy= 0.859
Step 7800, Minibatch Loss= 0.4608, Training Accuracy= 0.852
Step 8000, Minibatch Loss= 0.5501, Training Accuracy= 0.828
Step 8200, Minibatch Loss= 0.7387, Training Accuracy= 0.758
Step 8400, Minibatch Loss= 0.6295, Training Accuracy= 0.773
Step 8600, Minibatch Loss= 0.4497, Training Accuracy= 0.875
Step 8800, Minibatch Loss= 0.4465, Training Accuracy= 0.867
Step 9000, Minibatch Loss= 0.3878, Training Accuracy= 0.875
Step 9200, Minibatch Loss= 0.4795, Training Accuracy= 0.883
Step 9400, Minibatch Loss= 0.4143, Training Accuracy= 0.859
Step 9600, Minibatch Loss= 0.4545, Training Accuracy= 0.844
Step 9800, Minibatch Loss= 0.3253, Training Accuracy= 0.922
Step 10000, Minibatch Loss= 0.4482, Training Accuracy= 0.859
Optimization Finished!
Testing Accuracy: 0.8984375
real 5m24.519s
user 27m32.158s
sys 6m12.759s
2. On my machine with 2 core, 16GB RAM and NVidia GTX 1070 Ti graphics card:
time python recurrent_network.py
/home/alice/anaconda3/lib/python3.6/site-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.
from ._conv import register_converters as _register_converters
WARNING:tensorflow:From recurrent_network.py:21: read_data_sets (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.
Instructions for updating:
Please use alternatives such as official/mnist/dataset.py from tensorflow/models.
WARNING:tensorflow:From /home/alice/anaconda3/lib/python3.6/site-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:260: maybe_download (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version.
Instructions for updating:
Please write your own downloading logic.
WARNING:tensorflow:From /home/alice/anaconda3/lib/python3.6/site-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:262: extract_images (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.
Instructions for updating:
Please use tf.data to implement this functionality.
Extracting /tmp/data/train-images-idx3-ubyte.gz
WARNING:tensorflow:From /home/alice/anaconda3/lib/python3.6/site-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:267: extract_labels (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.
Instructions for updating:
Please use tf.data to implement this functionality.
Extracting /tmp/data/train-labels-idx1-ubyte.gz
WARNING:tensorflow:From /home/alice/anaconda3/lib/python3.6/site-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:110: dense_to_one_hot (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.
Instructions for updating:
Please use tf.one_hot on tensors.
Extracting /tmp/data/t10k-images-idx3-ubyte.gz
Extracting /tmp/data/t10k-labels-idx1-ubyte.gz
WARNING:tensorflow:From /home/alice/anaconda3/lib/python3.6/site-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py:290: DataSet.__init__ (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.
Instructions for updating:
Please use alternatives such as official/mnist/dataset.py from tensorflow/models.
WARNING:tensorflow:From recurrent_network.py:77: softmax_cross_entropy_with_logits (from tensorflow.python.ops.nn_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Future major versions of TensorFlow will allow gradients to flow
into the labels input on backprop by default.
See @{tf.nn.softmax_cross_entropy_with_logits_v2}.
2018-09-27 09:39:34.387663: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.1 SSE4.2
2018-09-27 09:39:34.488027: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:897] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2018-09-27 09:39:34.488501: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1392] Found device 0 with properties:
name: GeForce GTX 1070 Ti major: 6 minor: 1 memoryClockRate(GHz): 1.683
pciBusID: 0000:01:00.0
totalMemory: 7.93GiB freeMemory: 7.72GiB
2018-09-27 09:39:34.488518: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1471] Adding visible gpu devices: 0
2018-09-27 09:39:34.737643: I tensorflow/core/common_runtime/gpu/gpu_device.cc:952] Device interconnect StreamExecutor with strength 1 edge matrix:
2018-09-27 09:39:34.737678: I tensorflow/core/common_runtime/gpu/gpu_device.cc:958] 0
2018-09-27 09:39:34.737685: I tensorflow/core/common_runtime/gpu/gpu_device.cc:971] 0: N
2018-09-27 09:39:34.737899: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1084] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 7451 MB memory) -> physical GPU (device: 0, name: GeForce GTX 1070 Ti, pci bus id: 0000:01:00.0, compute capability: 6.1)
Step 1, Minibatch Loss= 2.6665, Training Accuracy= 0.102
Step 200, Minibatch Loss= 2.1436, Training Accuracy= 0.273
Step 400, Minibatch Loss= 1.9958, Training Accuracy= 0.398
Step 600, Minibatch Loss= 1.8857, Training Accuracy= 0.391
Step 800, Minibatch Loss= 1.6399, Training Accuracy= 0.531
Step 1000, Minibatch Loss= 1.5933, Training Accuracy= 0.508
Step 1200, Minibatch Loss= 1.6511, Training Accuracy= 0.391
Step 1400, Minibatch Loss= 1.4492, Training Accuracy= 0.523
Step 1600, Minibatch Loss= 1.3485, Training Accuracy= 0.570
Step 1800, Minibatch Loss= 1.3464, Training Accuracy= 0.570
Step 2000, Minibatch Loss= 1.3131, Training Accuracy= 0.570
Step 2200, Minibatch Loss= 1.1193, Training Accuracy= 0.672
Step 2400, Minibatch Loss= 1.2354, Training Accuracy= 0.617
Step 2600, Minibatch Loss= 1.0234, Training Accuracy= 0.719
Step 2800, Minibatch Loss= 1.1582, Training Accuracy= 0.656
Step 3000, Minibatch Loss= 1.0689, Training Accuracy= 0.570
Step 3200, Minibatch Loss= 0.9953, Training Accuracy= 0.656
Step 3400, Minibatch Loss= 0.8416, Training Accuracy= 0.742
Step 3600, Minibatch Loss= 0.9553, Training Accuracy= 0.758
Step 3800, Minibatch Loss= 0.8145, Training Accuracy= 0.750
Step 4000, Minibatch Loss= 0.8229, Training Accuracy= 0.758
Step 4200, Minibatch Loss= 0.8903, Training Accuracy= 0.695
Step 4400, Minibatch Loss= 0.6680, Training Accuracy= 0.820
Step 4600, Minibatch Loss= 0.7681, Training Accuracy= 0.742
Step 4800, Minibatch Loss= 0.6999, Training Accuracy= 0.836
Step 5000, Minibatch Loss= 0.9245, Training Accuracy= 0.758
Step 5200, Minibatch Loss= 0.7183, Training Accuracy= 0.758
Step 5400, Minibatch Loss= 0.6794, Training Accuracy= 0.828
Step 5600, Minibatch Loss= 0.5801, Training Accuracy= 0.820
Step 5800, Minibatch Loss= 0.6639, Training Accuracy= 0.758
Step 6000, Minibatch Loss= 0.7383, Training Accuracy= 0.781
Step 6200, Minibatch Loss= 0.7214, Training Accuracy= 0.789
Step 6400, Minibatch Loss= 0.6905, Training Accuracy= 0.766
Step 6600, Minibatch Loss= 0.6147, Training Accuracy= 0.820
Step 6800, Minibatch Loss= 0.5964, Training Accuracy= 0.859
Step 7000, Minibatch Loss= 0.6019, Training Accuracy= 0.820
Step 7200, Minibatch Loss= 0.5961, Training Accuracy= 0.805
Step 7400, Minibatch Loss= 0.6146, Training Accuracy= 0.820
Step 7600, Minibatch Loss= 0.5122, Training Accuracy= 0.781
Step 7800, Minibatch Loss= 0.7244, Training Accuracy= 0.781
Step 8000, Minibatch Loss= 0.5255, Training Accuracy= 0.828
Step 8200, Minibatch Loss= 0.3798, Training Accuracy= 0.898
Step 8400, Minibatch Loss= 0.3982, Training Accuracy= 0.891
Step 8600, Minibatch Loss= 0.5743, Training Accuracy= 0.805
Step 8800, Minibatch Loss= 0.5829, Training Accuracy= 0.820
Step 9000, Minibatch Loss= 0.4793, Training Accuracy= 0.906
Step 9200, Minibatch Loss= 0.5694, Training Accuracy= 0.852
Step 9400, Minibatch Loss= 0.5455, Training Accuracy= 0.828
Step 9600, Minibatch Loss= 0.4215, Training Accuracy= 0.867
Step 9800, Minibatch Loss= 0.5300, Training Accuracy= 0.805
Step 10000, Minibatch Loss= 0.3755, Training Accuracy= 0.875
Optimization Finished!
Testing Accuracy: 0.8828125
real 1m22.601s
user 1m21.002s
sys 0m7.588s
In summary, to compare the real time:
Machine Config Real time
----------- ------------- ----------------
Enterprise server 2 Xeon, 48 cores/256GB RAM 5m24.519s
My Machine 1 Celeron, 2 cores/16GB, NVidia 1070 Ti 1m21.002s
My Machine vs the enterprise server, is about 4X faster, given Xeon cores are much more powerful, 4X is impressive on a modest machine.
Conclusion:
This is typical image recognition application, you can extrapolate any image recognition, such as facial, or language processing that use neural net, will greatly benefit from having GPU in place. Using CPU to do deep learning is not optimal and good use of HW resource.